前提背景
现在有一个博客系统, 主要功能分为三块, 发布博客, 获取博客, 关注好友, 发布博客也就是可以发布文字, 视频, 图片,
关注好友为,用户可以关注其他人, 获取博客也就是用户可以刷新手机页面, 一次性获取固定条数(这里 以20为例)的微博, 到达底部后继续刷新按照时间顺序显示后续20条博客, 其他功能转发, 评论, 收藏, 点赞这里不做讨论
性能指标估计
系统按10亿用户设计,按20%日活估计,大约有2亿日活用户(DAU),其中每个日活用户每天发表一条微博,并且平均有500个关注者。
而对于系统所需的存储空间,我们做如下估算。
文本内容存储空间
遵循惯例,每条博客140个字,如果以UTF8编码存储汉字计算,则每条博客需要small140times3=420𝑠𝑚𝑎𝑙𝑙140𝑡𝑖𝑚𝑒𝑠3=420个字节的存储空间。除了汉字内容以外,每条博客还需要存储博客ID、用户ID、时间戳、经纬度等数据,按80个字节计算。那么每天新发表博客文本内容需要的存储空间为100GB。
small2亿times(420B+80B)=100GB/天𝑠𝑚𝑎𝑙𝑙2亿𝑡𝑖𝑚𝑒𝑠(420𝐵+80𝐵)=100𝐺𝐵/天
多媒体文件存储空间
除了140字文本内容,博客还可以包含图片和视频,按每5条博客包含一张图片,每10条博客包含一个视频估算,每张图片500KB,每个视频2MB,每天还需要60TB的多媒体文件存储空间。
small2亿div5times500KB+2亿div10times2MB=60TB/天𝑠𝑚𝑎𝑙𝑙2亿𝑑𝑖𝑣5𝑡𝑖𝑚𝑒𝑠500𝐾𝐵+2亿𝑑𝑖𝑣10𝑡𝑖𝑚𝑒𝑠2𝑀𝐵=60𝑇𝐵/天
对于刷博客的访问并发量,我们做如下估算。
QPS
假设两亿日活用户每天浏览两次博客,每次向上滑动或者进入某个人的主页10次,每次显示20条博客,每天刷新博客次数40亿次,即40亿次博客查询接口调用,平均QPS大约5万。
small40亿div(24times60times60)=46296/秒𝑠𝑚𝑎𝑙𝑙40亿𝑑𝑖𝑣(24𝑡𝑖𝑚𝑒𝑠60𝑡𝑖𝑚𝑒𝑠60)=46296/秒
高峰期QPS按平均值2倍计算,所以系统需要满足10万QPS。
网络带宽
10万QPS刷新请求,每次返回博客20条,那么每秒需访问200万条博客。按此前估计,每5条博客包含一张图片,每10条博客包含一个视频,需要的网络总带宽为4.8Tb/s。
small(200万div5times500KB+200万div10times2MB)times8bit=4.8Tb/s𝑠𝑚𝑎𝑙𝑙(200万𝑑𝑖𝑣5𝑡𝑖𝑚𝑒𝑠500𝐾𝐵+200万𝑑𝑖𝑣10𝑡𝑖𝑚𝑒𝑠2𝑀𝐵)𝑡𝑖𝑚𝑒𝑠8𝑏𝑖𝑡=4.8𝑇𝑏/𝑠
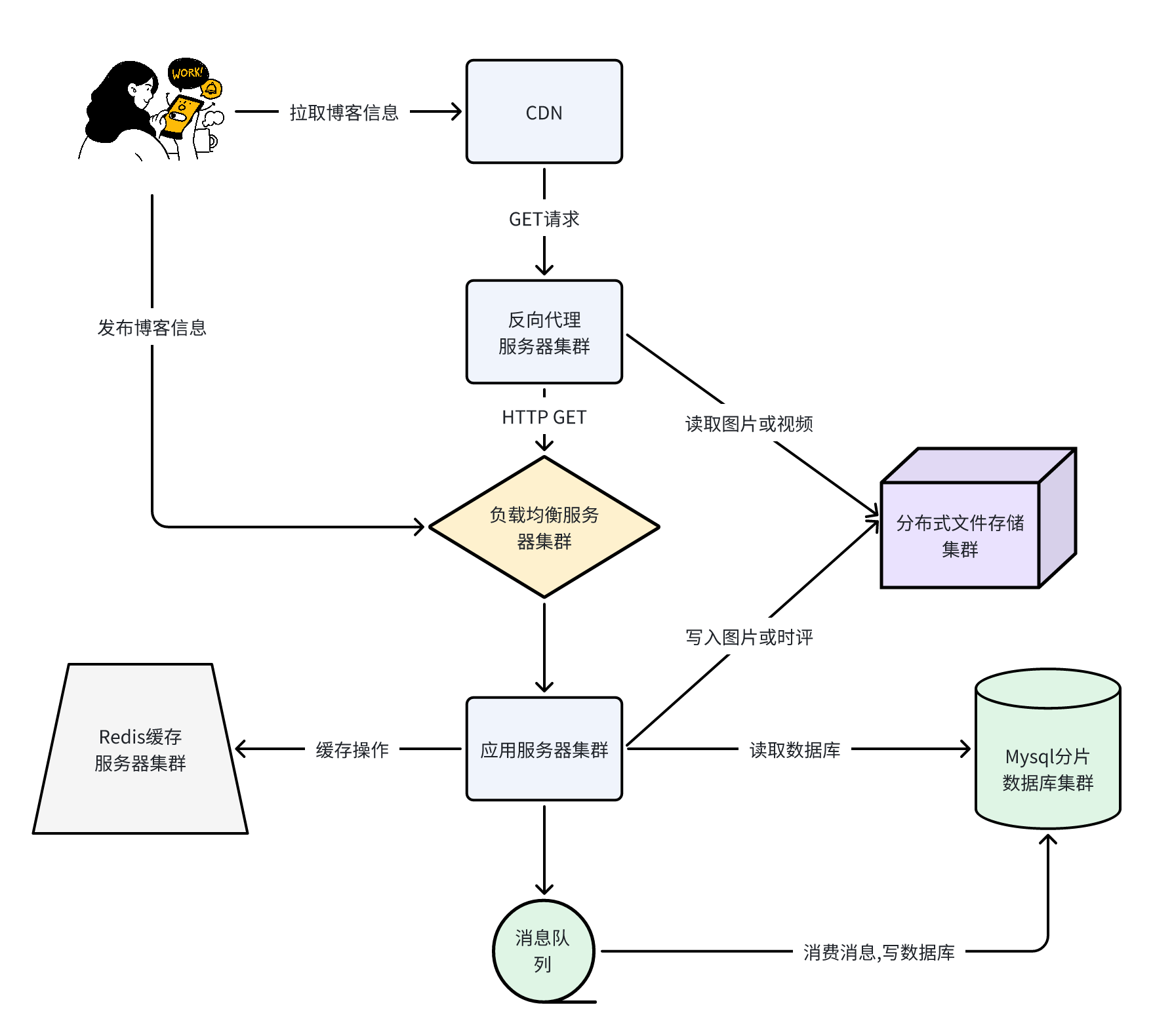
大致设计
Get请求链路分析
get请求主要用来用户获取博客数据用, 用户请求首先通过CDN访问数据中心, 图片以及视频等极耗带宽的请求,绝大部分可以被CDN缓存命中,也就是说,4.8Tb/s的带宽压力,90%以上可以通过CDN消化掉。
借用阿里云官网的例子,来简单介绍CDN的工作原理。假设通过CDN加速的域名为www.a.com,接入CDN网络,开始使用加速服务后,当终端用户(北京)发起HTTP请求时,处理流程如下:
当终端用户(北京)向www.a.com下的指定资源发起请求时,首先向LDNS(本地DNS)发起域名解析请求。
LDNS检查缓存中是否有www.a.com的IP地址记录。如果有,则直接返回给终端用户;如果没有,则向授权DNS查询。
当授权DNS解析www.a.com时,返回域名CNAME www.a.tbcdn.com对应IP地址。
域名解析请求发送至阿里云DNS调度系统,并为请求分配最佳节点IP地址。
LDNS获取DNS返回的解析IP地址。
用户获取解析IP地址。
用户向获取的IP地址发起对该资源的访问请求。
如果该IP地址对应的节点已缓存该资源,则会将数据直接返回给用户,例如,图中步骤7和8,请求结束。
如果该IP地址对应的节点未缓存该资源,则节点向源站发起对该资源的请求。获取资源后,结合用户自定义配置的缓存策略,将资源缓存至节点,例如,图中的北京节点,并返回给用户,请求结束。
没有被CDN命中的请求,一部分是图片和视频请求,其余主要是用户刷新博客请求、查看用户信息请求等,这些请求到达数据中心的反向代理服务器。反向代理服务器检查本地缓存(例如NGINX服务器上的缓存)是否有请求需要的内容。如果有,就直接返回;如果没有,对于图片和视频文件,会通过分布式文件存储集群获取相关内容并返回。分布式文件存储集群中的图片和视频是用户发表博客的时候,上传上来的。
对于用户博客内容等请求,如果反向代理服务器没有缓存,就会通过负载均衡服务器到达应用服务器处理。应用服务器首先会从Redis缓存服务器中,检索当前用户关注的好友发表的最新微博,并构建一个结果页面返回。如果Redis中缓存的博客数据量不足,构造不出一个结果页面需要的20条博客,应用服务器会继续从MySQL分片数据库中查找数据。
相当于设计了设计了一个三级缓存(CDN缓存, NGINX缓存, Redis缓存), 来避免大量查询走数据库
Post链路分析
当用户发布一篇博客时, 不需要走CDN缓存, 直接通过负载均衡到应用服务器上, 应用服务器之后将博客数据写到Redis和分片数据库中(也就是分表), 但是如果直接写数据库的话, 如果有高并发的写请求可能导致数据库过载, 因此一系列写请求比如: 发表博客、关注好友、评论博客等,都写入到消息队列服务器, 再由消费者程序从消息队列中按照一定的速度来消费消息, 并写入数据库, 保证数据库的负载压力不会突然增加
详细设计
关于发表, 订阅问题
当用户关注好友后, 如何快速得到所有好友的最新发表的博客内容,即发表/订阅问题,是这类系统的核心业务问题。也就是Feed流该如何设计,这里我们详细展开讲一下
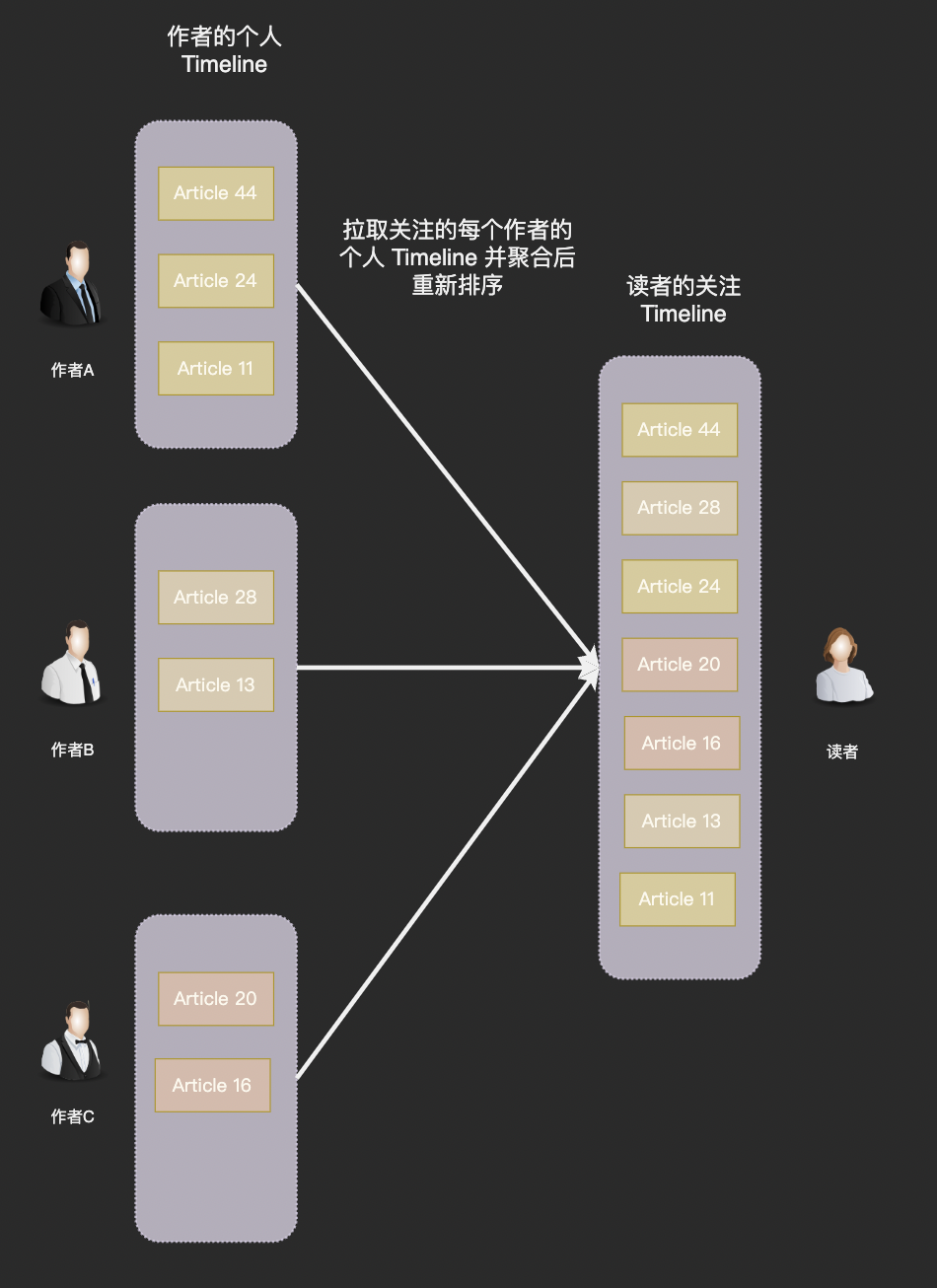
拉模式
一部分工程师认为应该在查询时首先查询用户关注的所有创作者 uid,然后查询他们发布的所有文章,最后按照发布时间降序排列
使用拉模型方案用户每打开一次「关注页」系统就需要读取 N 个人的文章(N 为用户关注的作者数), 因此拉模型也被称为读扩散。
拉模型不需要存储额外的数据,而且实现比较简单:发布文章时只需要写入一条 articles 记录,用户关注(或取消关注)也只需要增删一条 followings 记录。特别是当粉丝数特别多的头部作者发布内容时不需要进行特殊处理,等到读者进入关注页时再计算就行了。
拉模型的问题同样也非常明显,每次阅读「关注页」都需要进行大量读取和一次重新排序操作,若用户关注的人数比较多一次拉取的耗时会长到难以接受的地步。对于用户来说并不友好
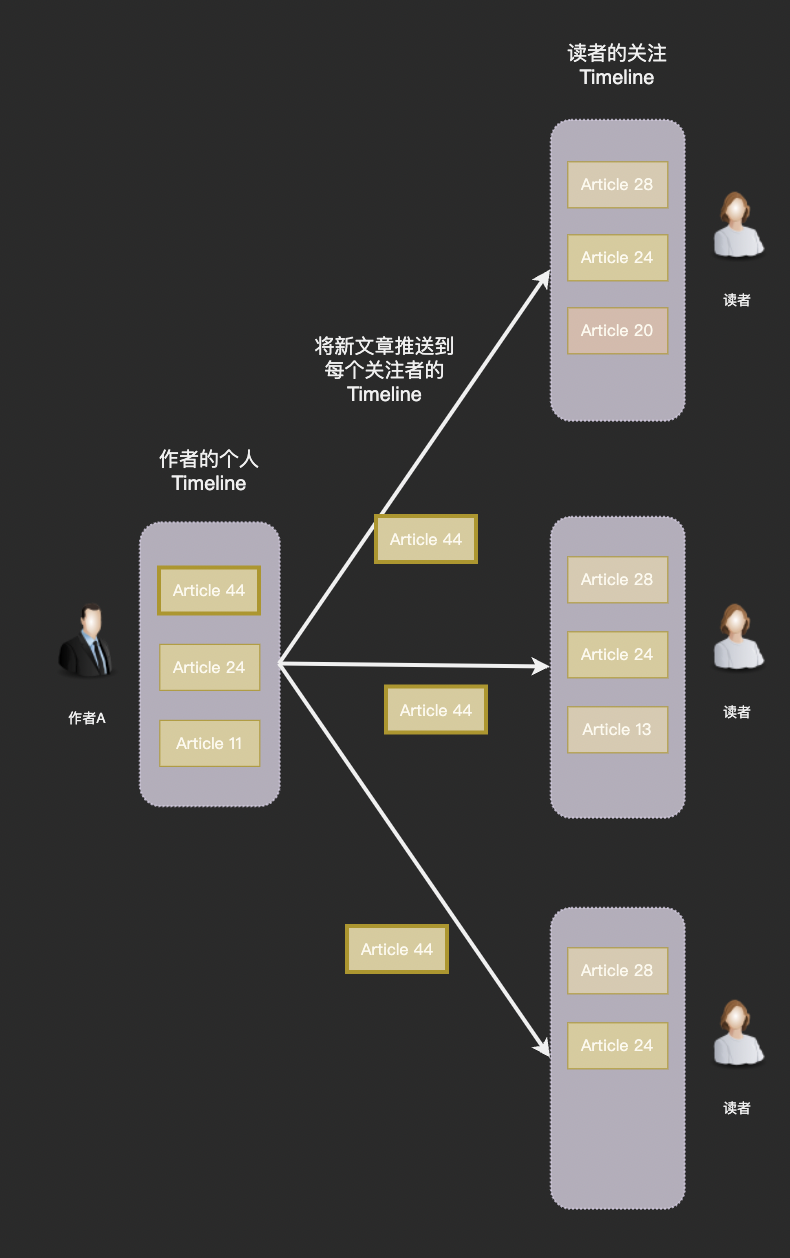
推模式
另一部分工程师认为在创作者发布文章时就应该将新文章写入到粉丝的关注 Timeline,用户每次阅读只需要到自己的关注 Timeline 拉取就可以了
使用推模型方案创作者每次发布新文章系统就需要写入 M 条数据(M 为创作者的粉丝数),因此推模型也被称为写扩散。推模型的好处在于拉取操作简单高效,但是缺点一样非常突出。
首先,在每篇文章要写入 M 条数据,在如此恐怖的放大倍率下关注 Timeline 的总体数据量将达到一个惊人数字。而粉丝数有几十万甚至上百万的头部创作者每次发布文章时巨大的写入量都会导致服务器地震。
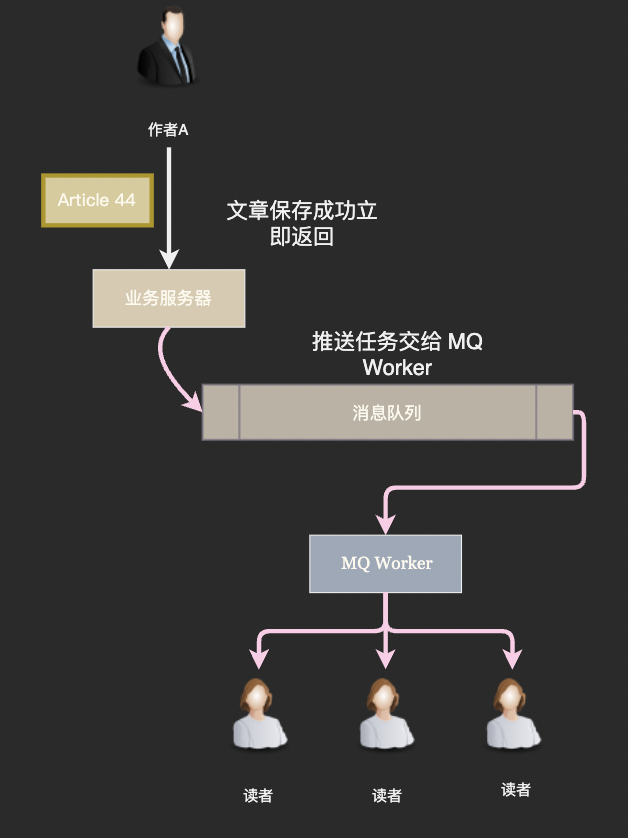
通常为了发布者的体验文章成功写入就向前端返回成功,然后通过消息队列异步地向粉丝的关注 Timeline 推送文章。
在线推, 离线拉
| | |
|---|
| | 逻辑复杂
消耗大量存储空间
粉丝数多的时候会是灾难
系统不友好 |
| | |
简而概之就是一句话,推模式对用户友好,对系统不友好而拉模式系统友好,而对用户不友好, 但在实际中, 一般一个用户关注2000人的都比较少, 所以乍看上去拉模型优点多多,但是 Feed 流是一个极度读写不平衡的场景,读请求数比写请求数高两个数量级也不罕见,对于服务器来说, 这使得拉模型消耗的 CPU 等资源反而更高。
此外推送可以慢慢进行,但是用户很难容忍打开页面时需要等待很长时间才能看到内容(很长:指等一秒钟就觉得卡)。 因此拉模型读取效率低下的缺点使得它的应用受到了极大限制。
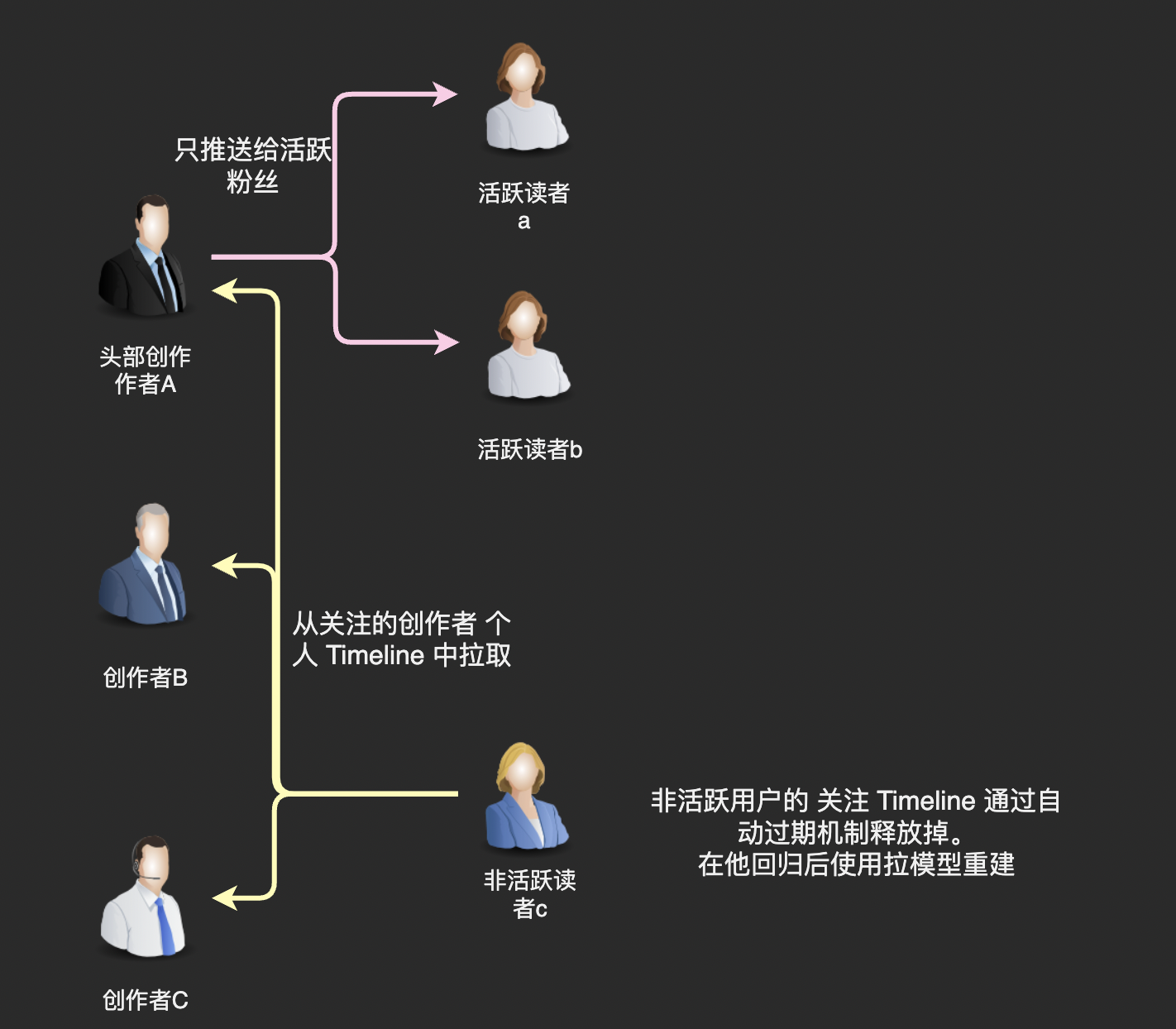
我们回过头来看困扰推模型的这个问题「粉丝数多的时候会是灾难」,我们真的需要将文章推送给作者的每一位粉丝吗?
仔细想想这也没有必要,我们知道粉丝群体中活跃用户是有限的,我们完全可以只推送给活跃粉丝,不给那些已经几个月没有启动 App 的用户推送新文章。
至于不活跃的用户,在他们回归后使用拉模型重新构建一下关注 Timeline 就好了。因为不活跃用户回归是一个频率很低的事件,我们有充足的计算资源使用拉模型进行计算。
因为活跃用户和不活跃用户常常被叫做「在线用户」和「离线用户」,所以这种通过推拉结合处理头部作者发布内容的方式也被称为「在线推,离线拉」。我们的博客系统采用这种方式
关于缓存的存储策略
通过前面的分析可以看到, 博客系统是一个高并发读写操作的场景, 10万QPS刷新请求,每个请求需要返回20条微博,如果全部到数据库中查询的话,数据库的QPS将达到200万,即使是使用分片的分布式数据库,这种压力也依然是无法承受的。所以,我们需要大量使用缓存以改善性能,提高吞吐能力。
但是缓存的空间是有限的,我们必定不能将所有数据都缓存起来。一般缓存使用的是LRU淘汰算法,即当缓存空间不足时,将最近最少使用的缓存数据删除,空出缓存空间存储新数据。
但仔细分析一下, LRU算法适合我们业务场景么, 在拉模式下, 当用户刷新微博的时候, 我们需要确保其关注的好友最新发表的博客都能展示出来,如果其关注的某个好友较少有其他关注者,那么这个好友发表的博客就很可能会被LRU算法淘汰删除出缓存。对于这种情况,系统就不得不去数据库中进行查询。
而最关键的是,系统并不能知道哪些好友的数据通过读缓存就可以得到全部最新的博客,而哪些好友需要到数据库中查找。因此不得不全部到数据库中查找,这就失去了使用缓存的意义。
基于此,我们在该系统中使用时间淘汰算法,也就是将最近一定天数内发布的博客全部缓存起来,用户刷新的时候,只需要在缓存中进行查找。如果查找到的文章数满足一次返回的条数(20条),就直接返回给用户;如果&